Get Healthy!
Staying informed is also a great way to stay healthy. Keep up-to-date with all the latest health news here.
03 Aug
Cellphone Bans at School May Not Improve Reading Scores, Study Suggests
Psychologists at UCLA tested reading comprehension in more than 100 elementary school students and found those who owned cellphones had poorer scores – whether the phone was at school or at home.
31 Jul
What Dad Eats Before Conception May Influence Baby's Health
A new study suggests fathers who eat more ultra-processed foods before conception may influence their babies' birth weight and body composition.
30 Jul
Popular Eczema Remedy May Fall Short
A new study finds oral antihistamines may do little to ease eczema flare-ups and itchiness.
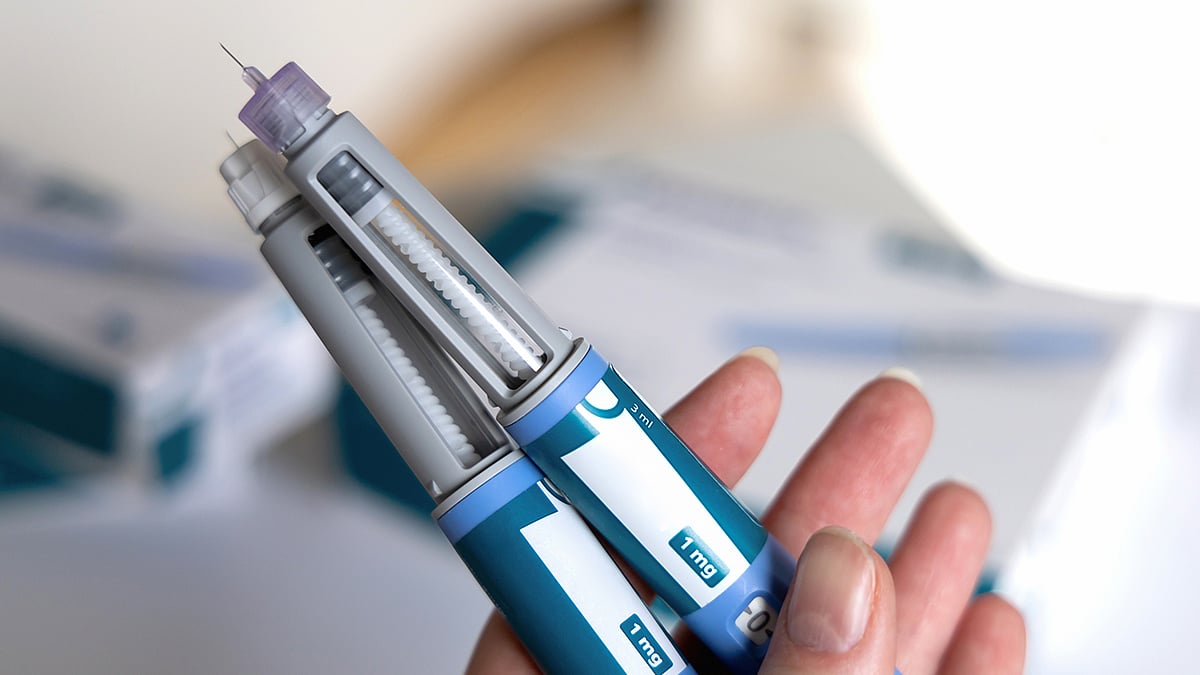
VA Launches Nationwide Trial Of GLP-1 Drug For Problem Drinking
Federal health officials have launched a nationwide clinical trial to find out whether a drug used to treat diabetes can help veterans cut back on drinking.
The U.S. Department of Veterans Affairs (VA) will test semaglutide, a GLP-1 receptor agonist, as a treatment for alcohol use disorder (AUD).
More than 400,000 veterans have been ...
- Ellyn Vohnoutka HealthDay Reporter
- |
- August 3, 2026
- |
- Full Page

Premature Menopause Linked To High Blood Pressure
Women who enter menopause at an earlier age have an increased risk of high blood pressure, a new study says.
Researchers found that nearly 23% of women with premature menopause and 19% of women with early menopause had high blood pressure, compared to under 17% of women with normal menopause, researchers found.
Overall, premature men...
- Dennis Thompson HealthDay Reporter
- |
- August 3, 2026
- |
- Full Page
.jpg?w=1920&h=1080&mode=crop&crop=focalpoint)
Once-Weekly Pill Could Revolutionize HIV Treatment
A new once-weekly pill could revolutionize regular care for patients with HIV, a new study says.
This experimental pill is as effective as one of today’s leading HIV therapies, researchers reported in The New England Journal of Medicine.
“The first ever weekly oral therapy for the treatment of HIV could offer wel...
- Dennis Thompson HealthDay Reporter
- |
- August 3, 2026
- |
- Full Page

Transgender 'Top Surgery' Patients Aren't Receiving Adequate Breast Cancer Advice, Researchers Say
Transgender individuals undergoing “top surgery” aren’t being provided adequate counseling about their future risk of breast cancer, a new study says.
Top surgery — gender-affirming mastectomy — might appear to reduce or eliminate breast cancer risk by removing most or all breast tissue, researchers said.
<...- Dennis Thompson HealthDay Reporter
- |
- August 3, 2026
- |
- Full Page

Does Childhood Divorce Increase Kids' Risk Of Adult Depression — Or Is It Other Parental Problems?
Kids whose parents divorce have higher odds of depression in adulthood — but the marital split might not be the main driver of these mood disorders.
Children of divorce have a 41% increased risk of depression as adults, researchers reported July 29 in the journal Psychiatry Research.
But that increased risk virtually d...
- Dennis Thompson HealthDay Reporter
- |
- August 3, 2026
- |
- Full Page

FTC Sues Hims & Hers Over Health Privacy And Billing Practices
The U.S. Federal Trade Commission (FTC) has sued telehealth company Hims & Hers, alleging it shared consumers' private health information with advertising platforms and unknowingly charged some customers for prescriptions.
The lawsuit, joined by California and Utah, was filed Wednesday in federal court in Northern California.
Him...
- Ellyn Vohnoutka HealthDay Reporter
- |
- July 31, 2026
- |
- Full Page

Family History Plays Role In Genetic Risk For Breast Cancer, Researchers Find
A woman’s genetic risk for breast cancer depends on her family history as well as the presence of cancer-causing mutations, a new study says.
Breast cancer risk among women tested for BRCA gene mutations shifted depending on the cancer history of family members, researchers reported July 30 in JAMA Network Open.
Among ...
- Dennis Thompson HealthDay Reporter
- |
- July 31, 2026
- |
- Full Page

What Dad Eats Before Conception May Influence Baby's Health
When it comes to preparing for a healthy pregnancy, the focus is usually on moms. But new research suggests dads' nutrition plays an important role, too.
"Maternal nutrition and health before, during and after the baby's birth have always received attention, but little is said about the role of the father's diet," said study author Daniela...
- HealthDay Staff HealthDay Reporter
- |
- July 31, 2026
- |
- Full Page

Daily Routine Key To Good Health, Study Says
Finding a comfortable, consistent daily schedule could be crucial to boosting your mental and physical health, a new study says.
People who maintain a consistent routine tend to have lower levels of pain and depression, researchers reported recently in the Journal of Behavioral Medicine.
There's a solid reason why: "If we ar...
- Dennis Thompson HealthDay Reporter
- |
- July 31, 2026
- |
- Full Page

Nicotine Levels Are Rising Among Teens Who Vape, New Study Warns
Vape devices are flooding teens’ bodies with increasingly heavy doses of addictive nicotine, a new study finds.
Average urine levels of a key nicotine metabolite, cotinine, nearly tripled among teenagers over a period of a few months in late 2024, researchers reported July 29 in JAMA Psychiatry.
Teens’ cotinine l...
- Dennis Thompson HealthDay Reporter
- |
- July 31, 2026
- |
- Full Page

Psilocybin Therapy Helps Ease Veterans' Severe PTSD, Pilot Study Finds
U.S. Army veteran Zachariah Collett served a 28-month combat tour in Iraq that left deep scars on his psyche.
After his medical retirement at age 25, due in part to post-traumatic stress disorder (PTSD), Collett suffered from nightmares and a short fuse. He felt constantly on guard and always angry.
“I was just absolutely tortu...
- Dennis Thompson HealthDay Reporter
- |
- July 31, 2026
- |
- Full Page

Scientists Defend Fauci's Pandemic Work As Senate Hearing Turns Bitter
More than 155 physicians, scientists and public health advocates signed a public letter defending Dr. Anthony Fauci, as he faced a hostile Senate hearing over his handling of the COVID-19 pandemic.
Fauci led the National Institute of Allergy and Infectious Diseases (NIAID) from 1984 until his retirement in 2022 and advised presi...
- Ellyn Vohnoutka HealthDay Reporter
- |
- July 30, 2026
- |
- Full Page

Vaping Is Likely Reshaping The Future Of Cancer In The US, Study Argues
E-cigarettes could be reshaping the future of cancer in the United States, by offering people a less-toxic option than smoking, a new study argues.
Smokers are increasingly switching to vaping and other forms of nicotine use, researchers reported July 27 in the journal JNCI Cancer Spectrum.
They’re also sticking with t...
- Dennis Thompson HealthDay Reporter
- |
- July 30, 2026
- |
- Full Page
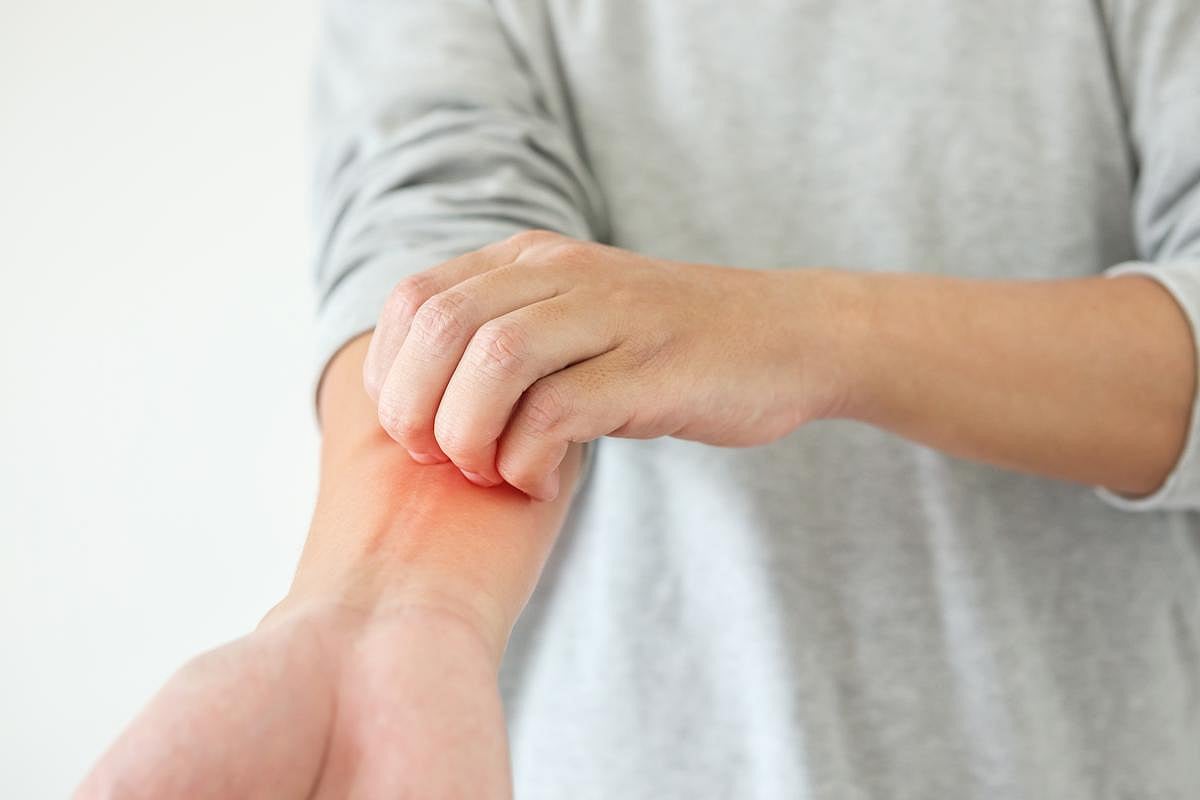
Study Questions Effectiveness of Antihistamines in Easing Eczema
People with eczema often take antihistamine pills, hoping to ease relentless itching.
But a new study finds they may do little to help and could even cause worrisome side effects.
A team led by Dr. Alexandro Chu, of McMaster University in Hamilton, Canada, reviewed 47 clinical trials involving more than 6,200 children and adults with...
- HealthDay Staff HealthDay Reporter
- |
- July 30, 2026
- |
- Full Page

Sugar Consumption Early In Life Linked To Increased Dementia Risk, World War II-Era Data Show
Feeding your toddler — or unborn child — less sugar might protect their brains from dementia much later in life, a new study says.
Children who endured World War II sugar rationing had an up to 23% lower risk of dementia in old age, compared to those born after rationing ended, researchers reported July 29 in the journal Ne...
- Dennis Thompson HealthDay Reporter
- |
- July 30, 2026
- |
- Full Page

Work Stress Harming Middle-Age Sleep, Study Says
Work stress could be eating away at the sleep of most middle-aged working folks, undermining their health, a new study says.
Nearly 70% of a small group of people ages 50 to 66 experienced persistent sleep problems, even though they had no history of sleep disorders, researchers reported July 28 in the journal Scientific Reports.<...
- Dennis Thompson HealthDay Reporter
- |
- July 30, 2026
- |
- Full Page

Cell Phone Ownership Linked To Lower Reading Skills In Elementary Students
Cell phones could be blunting young children’s reading skills, a new study says.
Elementary school students who simply owned a cell phone scored worse on reading comprehension tests, researchers reported recently in the journal Behavioral Sciences.
Whether the kid had the cell phone on them at school played no role in ...
- Dennis Thompson HealthDay Reporter
- |
- July 30, 2026
- |
- Full Page
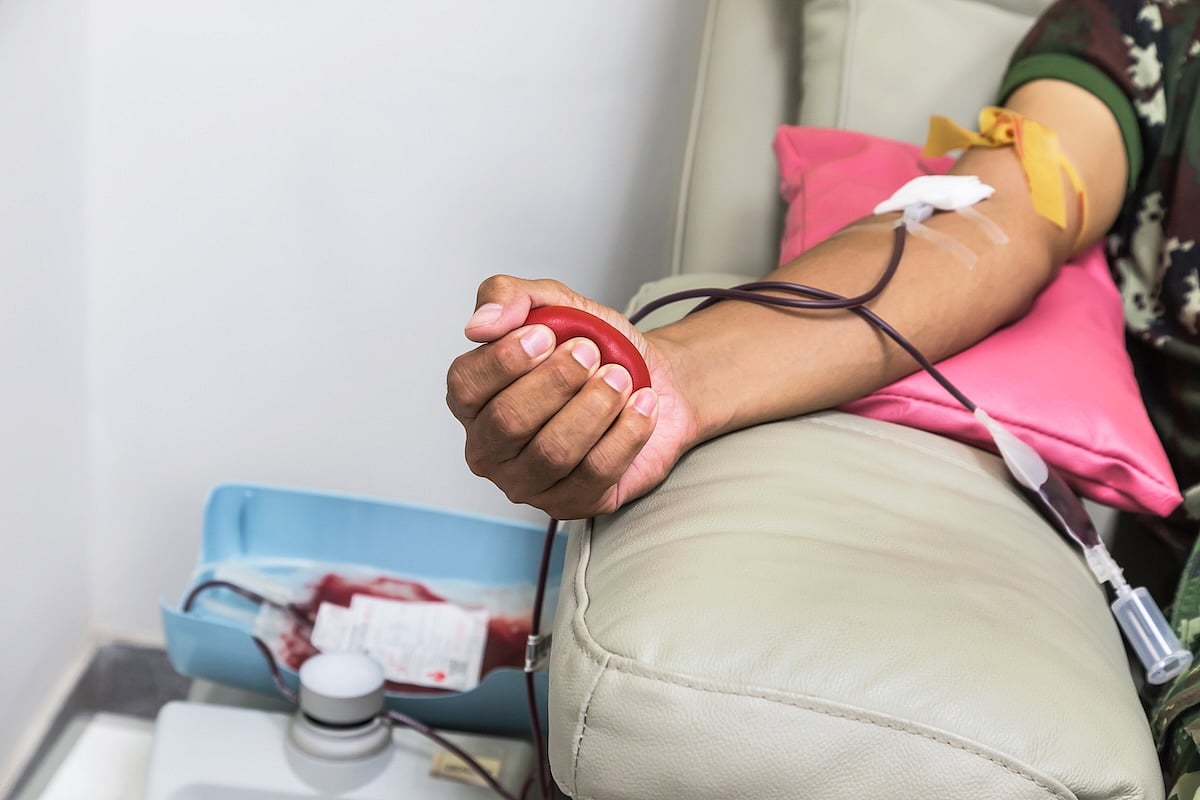
Red Cross Declares Rare National Blood Supply Crisis Amid Summer Shortfall
The American Red Cross has declared a national blood supply crisis for only the second time in its history, warning a drop in donations is threatening the availability of blood nationwide.
The organization, which supplies about 40% of the nation's blood, said donations have fallen to a four-year summer low even as hospital demand rises dur...
- Ellyn Vohnoutka HealthDay Reporter
- |
- July 29, 2026
- |
- Full Page

More Women Drinking During Pregnancy
An increasing number of women drink during pregnancy, potentially risking the health of their unborn children, a new study says.
More than 1 in 7 women reported that they drank alcohol while pregnant in 2023-24, researchers reported July 27 in JAMA: The Journal of the American Medical Association.
That’s up from fewer ...
- Dennis Thompson HealthDay Reporter
- |
- July 29, 2026
- |
- Full Page

Not Just Pregnancy Fatigue: Could It Be Sleep Apnea?
Pregnancy can make you really sleepy. It can even make you snore. But when does that become more than just a normal part of pregnancy?
The American College of Chest Physicians says those symptoms could be signs of obstructive sleep apnea — a condition that often goes overlooked during pregnancy.
Now, the group has released its ...
- HealthDay Staff HealthDay Reporter
- |
- July 29, 2026
- |
- Full Page
